Project Outfits
Problem Statement



Below is a video demonstrating how the visually impaired identify clothing items.
Our Solution
Descriptive World Mobile App:
Descriptive World Cloud-Based App:
How Does It Work?



We use computer vision, natural language processing and text to speech technologies to identify clothing type, texture and color then narrate a description of the clothing item back to the user.
Approach
Ideation
We began by exploring ideas; Initially we were looking to develop a system that could narrate real-time events in the field of vision of a user wearing the Descriptive World headset. However the scope of this task was monumental for the limited time our team had to research, design, develop and test a solution (10 weeks.) So after discussing various use cases including helping shoppers find items in a grocery store, helping the visually impaired navigate a city environment, and a few other situations, we decided to keep our scope to an environment that is mostly controlled and free of distractions (which could interfere with our ability to accurately identify items.) This lead us to limiting our environment to the home and eventually narrowing our scope to clothing identification as a ideal problem to tackle that can bring value to the lives of those visually impaired.
Research
Our team met with subject matter experts in the field of technology usage for the visually impaired. We were given some great advice to keep our approach simplistic so that the learning curve for usage was small to none and suggestions for several possible directions to take this project. The subject experts also pointed us toward other similar products available on the market to see their implementations and how to improve upon their approaches.
Datasets
To build our computer vision models, we needed to evaluate a number of different clothing-related datasets to determine which will give us the best results for our vision of our project. After searching the internet for several days, we came upon several clothing datasets that were accessible for acedemic/research purposes. Details for each dataset are shown below.
|
Dataset |
# Classes |
# Attributes |
# Images |
Total Size of Dataset |
Type of Dataset & Annotation |
Preprocessing Required? |
Viable? |
|
46 |
16 |
289,229 |
16GB |
image + bounding box + landmarks |
Data augmentation to increase variability |
Yes |
|
|
13 |
12 |
286,743 |
17.2GB |
image + bounding box + landmarks + segmentation |
Limit classes to higher occurrences |
Yes |
|
|
20 |
2 |
5,403 |
7.0GB |
image + metadata |
Class balancing |
Yes |
|
|
Fabric Patterns* |
7 |
1 |
3,730 |
0.5GB |
image |
*Custom scraped and cleansed |
Yes |
|
58 |
10 |
44,000 |
16GB |
image + metadata |
Yes, unbalanced |
No |
|
|
10 |
1 |
60,000/ 10,000 |
10 MB |
URIs + Metadata |
Download images |
No |
Data Transformations
Below is a diagram of our approach to preparing the dataset for training with our model. This includes our filtering/sub-selecting the dataset, formatting the images for ingestion, and transforming/editing the images for increasing the number and variation of the samples used for training.
In the end, we ended up with around 130,000 images from DeepFashion2 that we training our model with. Each image was converted into a 640 px x 640 px size for input.
The input image size for the texture/pattern model was 320 px x 320 px.
Models
|
Object Detection Architecture |
Object Detection Method |
Backbone Model |
ML Framework |
Layers |
Pretrained Dataset |
Trained Clothing Dataset |
|
YOLOv5 or YOLOR |
Bounding box |
CSPDarknet |
PyTorch |
24 |
COCO |
DeepFashion, DeepFashion 2 Clothing Dataset Fabric Patterns |
|
Faster-RCNN |
Bounding Box |
VGG16 |
TensorFlow |
16 |
COCO |
DeepFashion 2 |
|
EfficientDet |
Bounding Box |
EfficientNet |
PyLightning, PyTorch |
36 |
ImageNet |
DeepFashion 2 |
|
Mask R-CNN |
Segmentation |
VGG16, Mobilenet V2 |
Keras, TensorFlow |
16 + 5 3 |
COCO, ImageNet |
DeepFashion 2 |
Model Evaluation
Below are the evaluation results for each of the model architectures we explored for building the primary clothing type identification model as well as our objective assessment of the model with real-world examples.
Model Architecture | # of Classes | Image Res / Total | Labels | Training Time | Precision | Recall | mAP@0.5 | Real-world Tests |
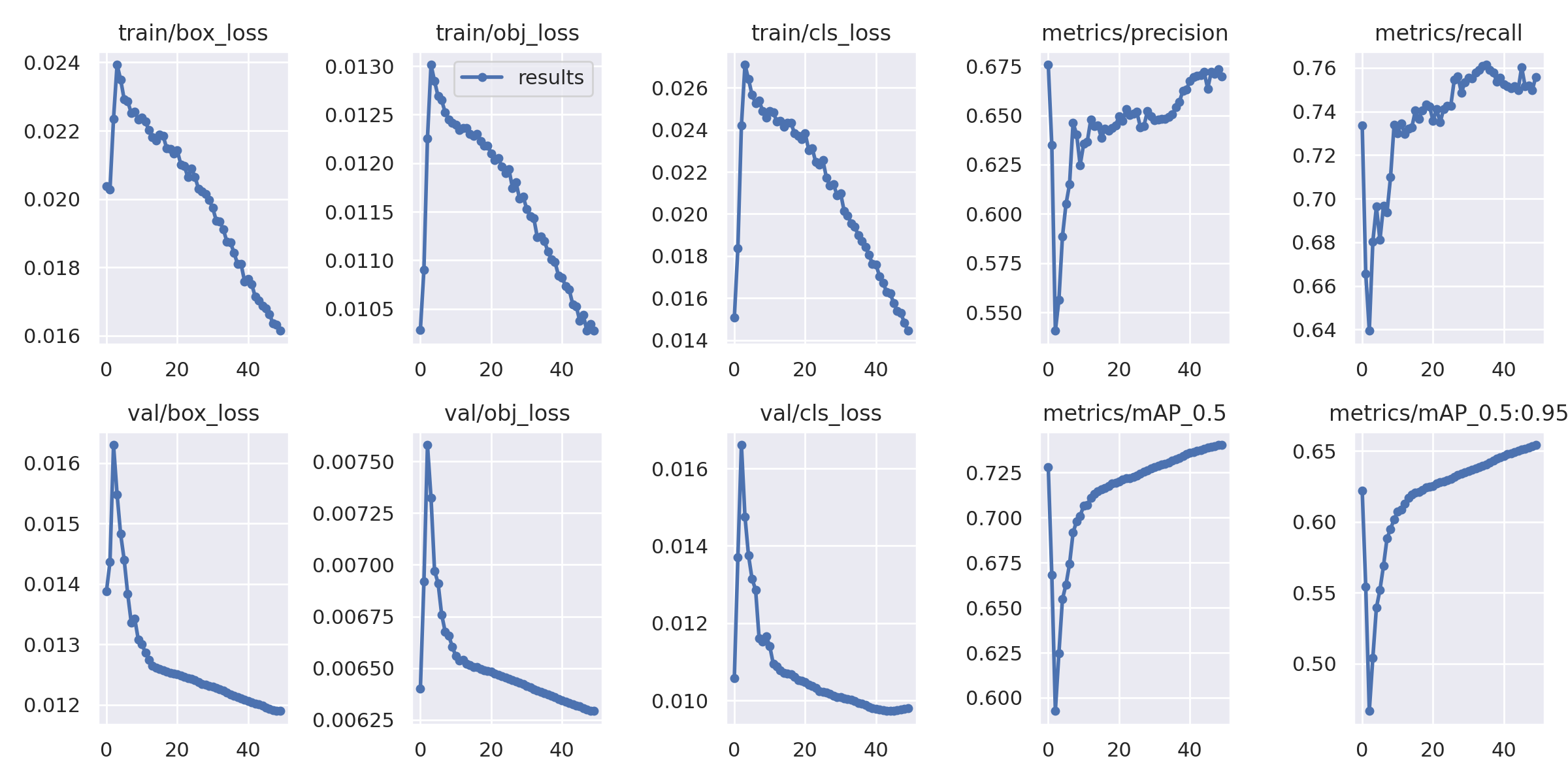
YOLOv5 | 11 + Background | 640×640 120,000 | 9220 | 16 hours 50 epochs | 0.67 | 0.756 | 0.74 | Satisfactory |
EfficientDet | 11 + Background | 512×512 110,000 | – | ~40 hours 40 epoch | – | – | – | Satisfactory 6/7 samples |
Faster-RCNN | 13 + Background | 640×640 480,000 | – | ~10 hours/ epoch | – | – | – | – |
Mask-RCNN | 13 + Background | 1024×1024 480,000 | – | ~20 days 50 epochs | – | – | – | 1/20 |
In the end only EfficientDet and YOLOv5 were able to produce inferences that were able to be tested with real-world examples at an satisfactory level. Note that EfficientDet doesn’t have values for precision, recall, and mAP@0.5 due to issuses causing the training to freeze when trying to calculate the rating for each epoch. Ultimately, we decided to use the YOLOv5 architecture for our final model due to its ease of building new models and its well documented examples from the community, which EfficientDet lacked.
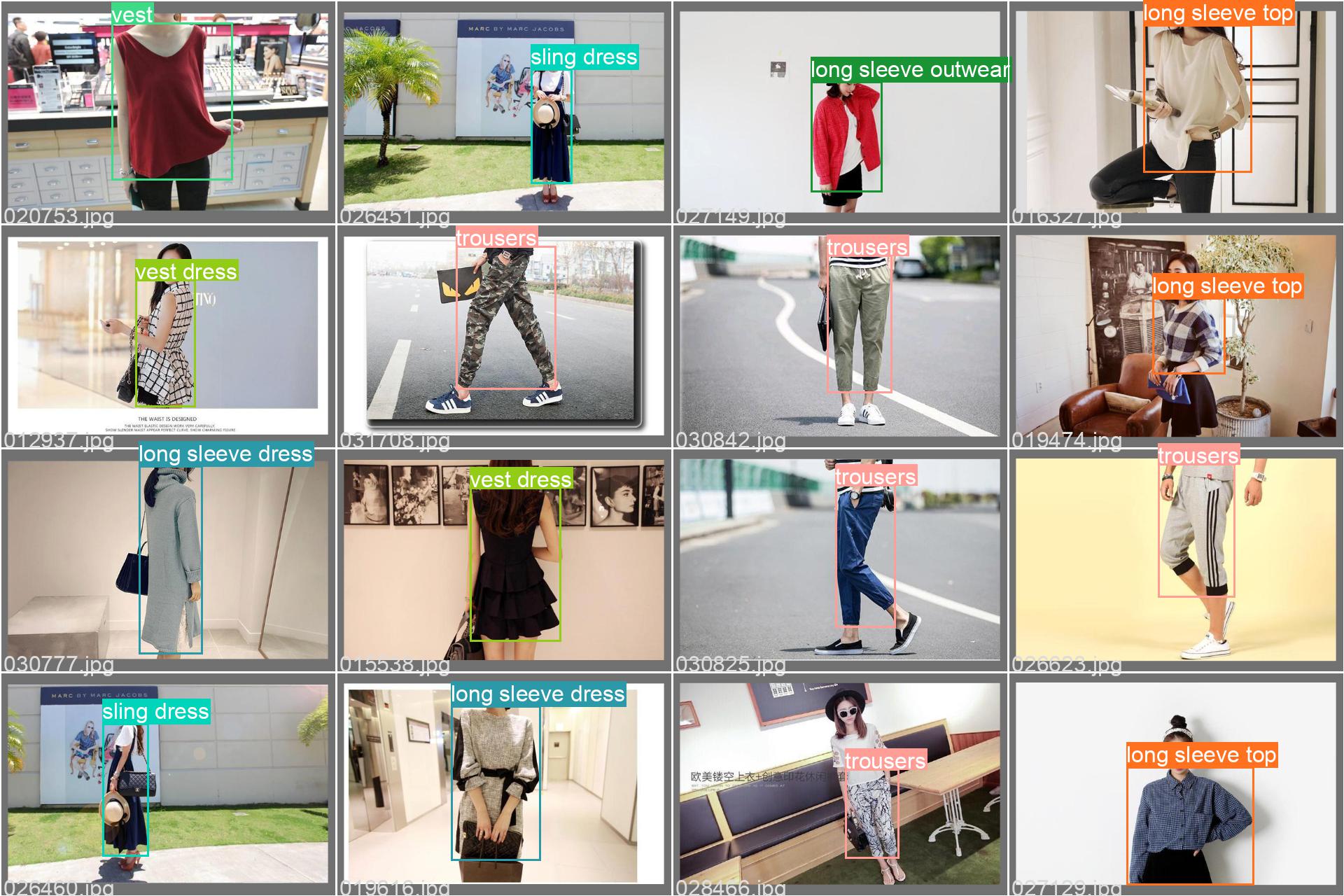
The final clothing type model contains 11 identifiable classes. This includes: short sleeve top, long sleeve top, long sleeve outerwear, short sleeve dress, long sleeve dress, sling dress, vest dress, vest, skirt, shorts, and trousers.
The texture/pattern model was also built using the YOLOv5 architecture and includes 7 identifiable patterns. These patterns include: plain (solid), stripe, polka dot, camouflage, zig-zag, paisley, floral, and plaid.
Final Model Hyperparameter Tuning
We attempted using different settings for hyperparameters but ended up getting the best results by just using the defaults on the YOLOv5 architecture.
Infrastructure Development
An architecture diagram of the Descriptive World eco-system. This includes the layout of the IOS version (top portion) and the AWS version (bottom portion).
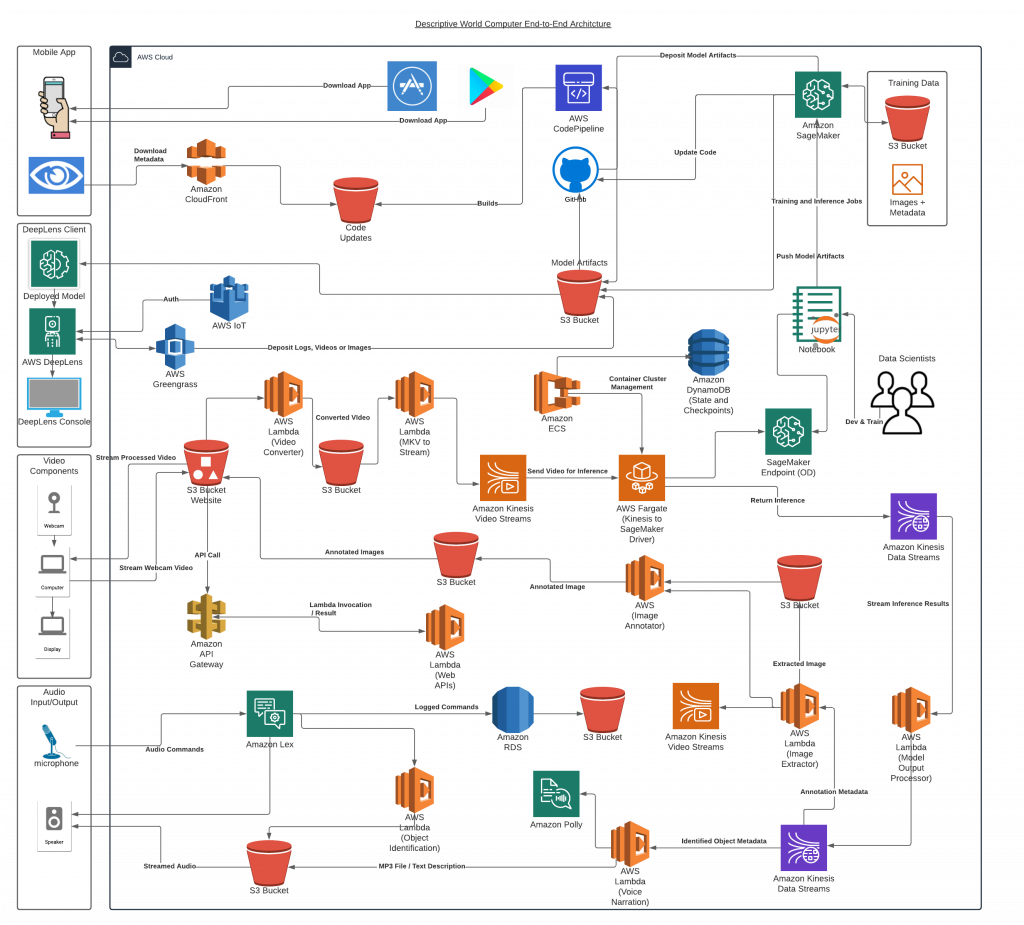
The IOS application built using local libraries for IOS in Swift and C as well as utilizing torchlight conversion for implementing our trained YOLO models.
The AWS version was built using several AWS applications/APIs which include a Kinesis video stream, s3 buckets, AWS lambdas, an AWS API gateway, Kinesis Data stream, Sagemaker endpoint, and Amazon Polly.
Security & Privacy
- Privacy By Design
- Videos/Images are not saved
- Backgrounds & Faces Removed, no other metadata stored
- Video streams sent to the cloud are encrypted
- Legislation and Governance
- Opt-in only to save images for improving training
- Provide user access to download their data and right to be forgotten
- Clearly defined Privacy Policy, Acceptable Use Policy and EULA
Ethical Considerations
We do not believe believe there are ethical implications of our product, however we do recognize that due to the dataset we are using we have limited classes (11) that are trained on common western clothing. We do not have data on other cultural outfits, however we would like to see if we can enrich our dataset with other ethnic clothing and add additional datasets in the future.
Product Development
We have treated Descriptive World as though it would be a product from day one, and we discuss more in the section on Go-to-Market. We gathered user requirements from our subject matter experts and performed user acceptance testing of our prototypes.
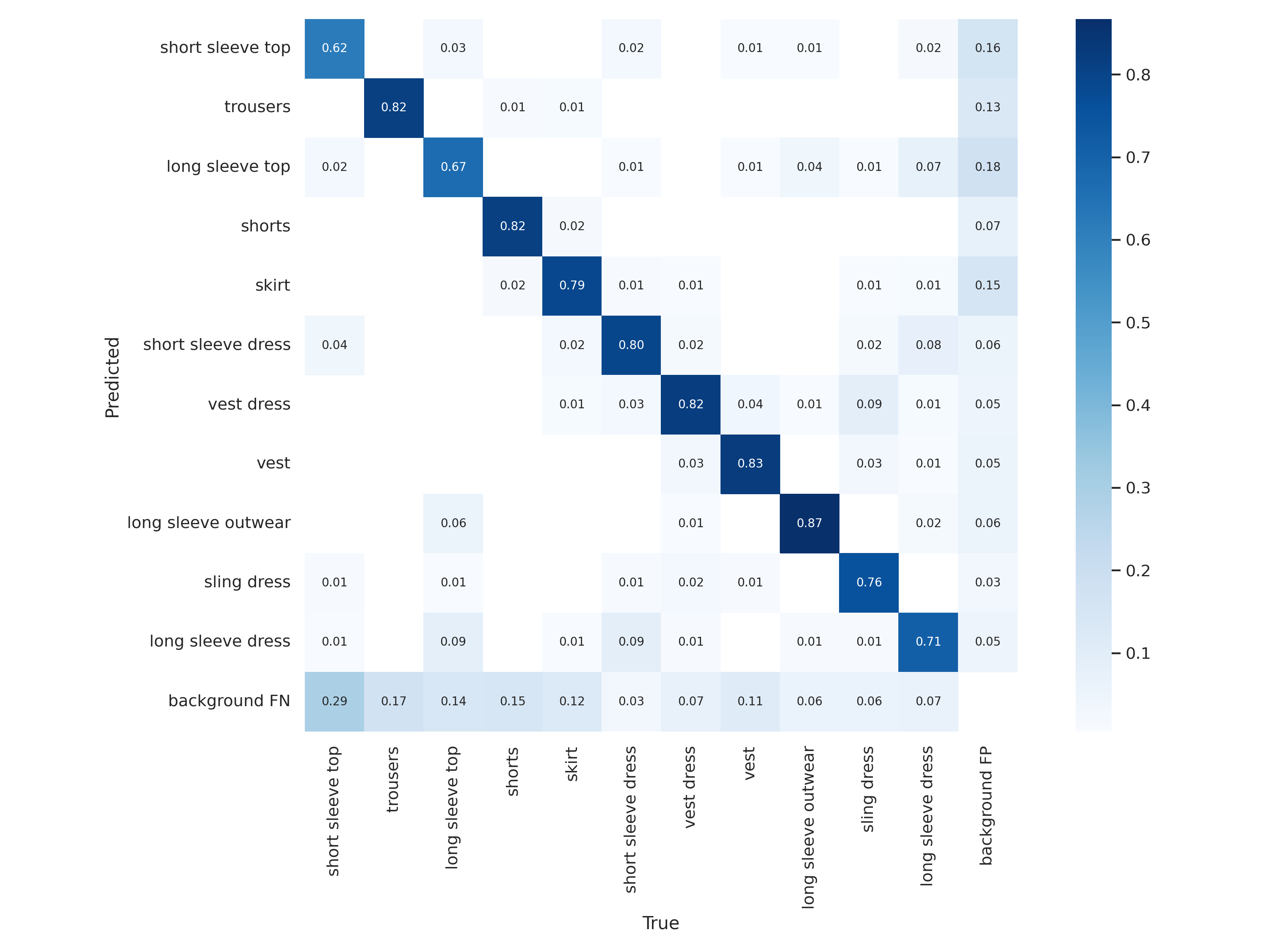
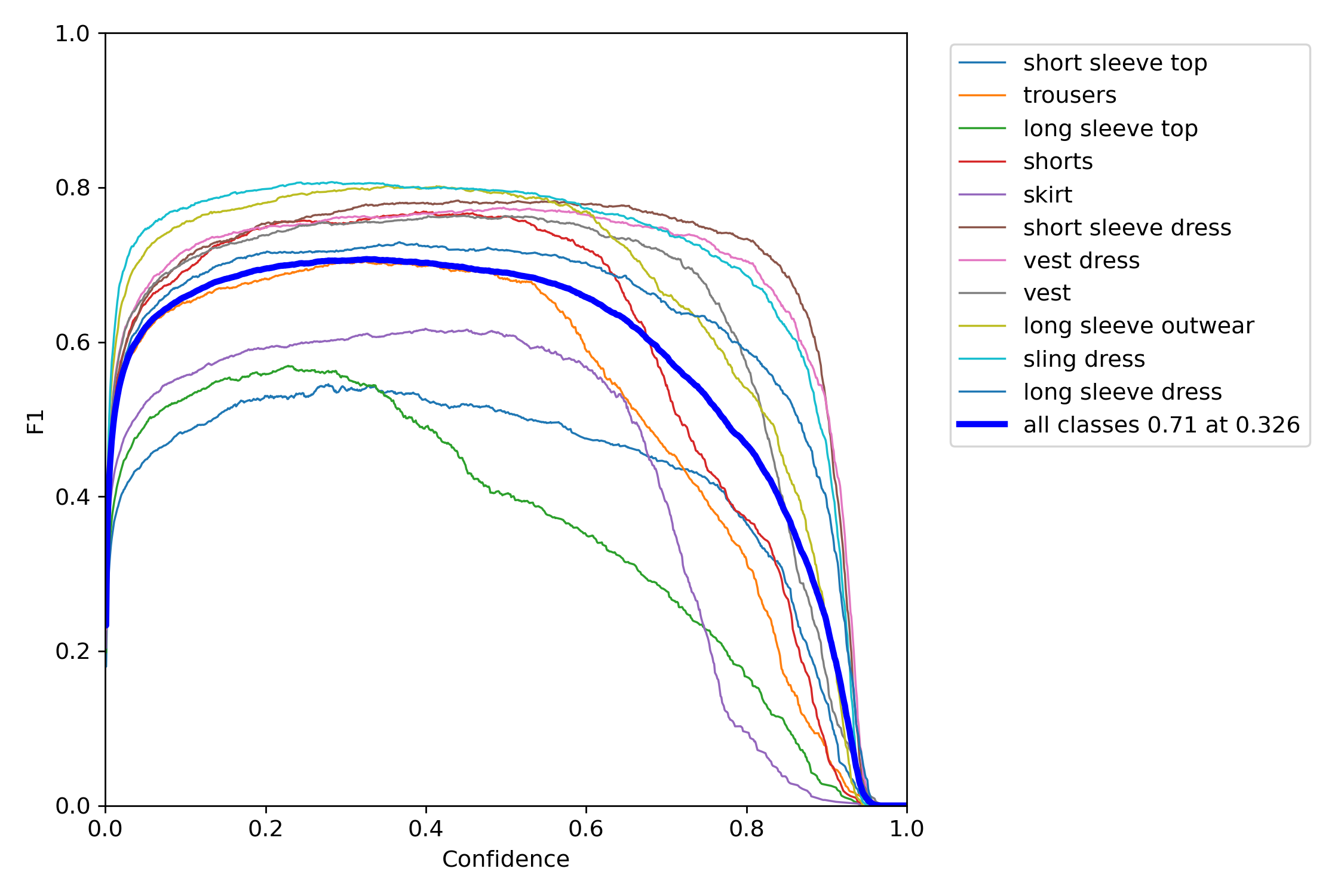
Results
Performance
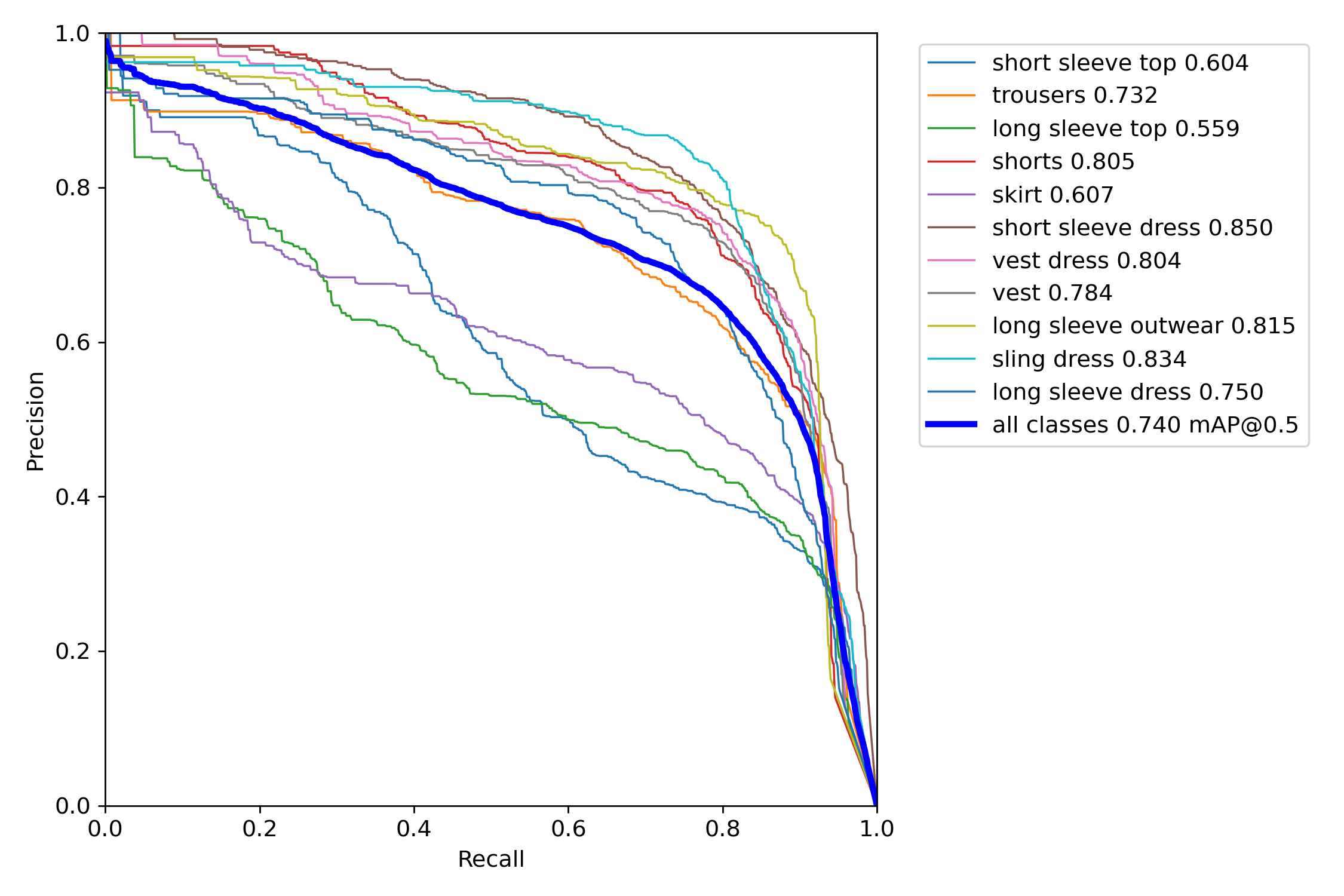
Our results for our final model for clothing type object detection (please click the image for closeup.) Overall we achieved a mean Average Precision (mAP@0.5) of 71% for identification.





Prototype
We prototyped a composite model of garment, color and texture identification. To achieve this, we use a pipeline with two YOLOv5 models loaded (garment and texture) with the texture extracted from the center portion of the garment. Color of the garment is determined with python library that matches the most dominate color with a CSS1 color name lookup. Model size ranges from 30 MB to 185 MB for the largest. Inference takes around ~0.1-0.3s per model.




Minimum Viable Product
– Accurately identify 11 classes of clothing items (object detection)
– Accurately identify 7 textures (pattern) of a clothing item (texture classification)
– Accurately identify the color of a clothing item (color identification)
– Implement a system to perform the aforementioned using state-of-the-art techniques
We were able to meet these objectives with our models and incorporate them in two different unique platforms. We developed two MVPs to demonstrate Descriptive World’s capabilities.
One entirely in in the cloud running on in AWS which exposes public APIs
and fronted by a demo web page and the other MVP is built on Apple IOS
which we have running on iPhone and is completely self-contained.
Our self-contained implementation requires no Internet access to operate and employs a lightweight model capable of running on mobile devices. Our cloud-based solution leverages AWS services and applications to ingest video in real-time, perform inference, and provide both a narration of the clothing items in the field of view as well as returning images with bounding boxes and confidence levels. Our model can detect any number of clothing items in the field of view. The iPhone app and our web implementation also leverage speech to text and natural language processing in order to process user commands, so that the user can interact with our system without the need for sight.
Our demo videos at the top of this page are the best illustrations of the functionality of our two MVPs work.
Check out the Github tab for all of the code used and tested in this project.
Business Plan
Business Model Canvas
Our business model canvas.

Competetive Analysis
Below is a comparison of how our approach performs compared to other solutions available on the market.
|
Company |
Product |
Voice Commands |
Voice Narration |
Clothing Recognition |
Color Recognition |
Texture Recognition |
Mobile Services |
100% Hands Free |
Cost |
|
Descriptive World |
Outfits |
YES |
YES |
YES |
YES |
YES |
YES |
YES |
~$2500 |
|
Envision |
Glasses |
YES |
YES |
YES |
YES |
NO |
NO |
NO |
~$3,800 |
|
Orcam |
MyEye |
YES |
YES |
YES |
YES |
NO |
NO |
NO |
~$3,700 |
|
eSight |
eSight 4 |
YES |
NO |
NO |
NO |
NO |
NO |
NO |
~$6,000 |
|
NuEyes |
NuEyes Pro |
YES |
NO |
NO |
NO |
NO |
NO |
NO |
~$6,000 |
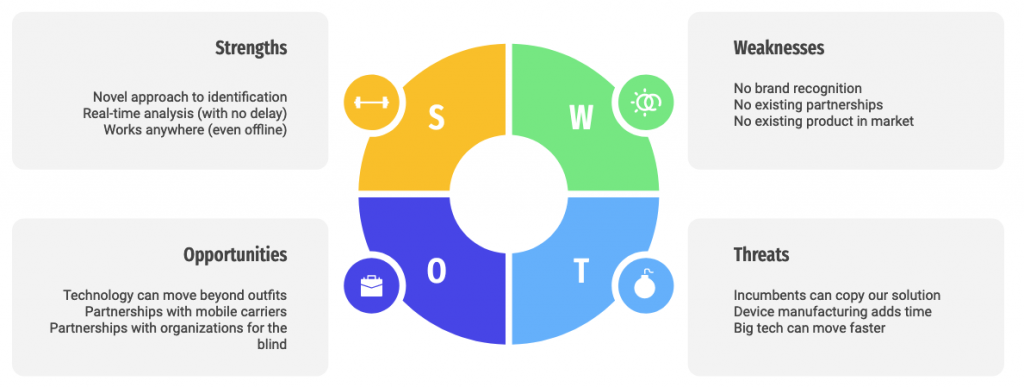
SWOT Analysis
A SWOT analysis on where Descriptive World Outfits is positioned in the market.